This project was done in conjunction with a presentation given at the Association of Education in Journalism and Mass Communication’s (AEJMC) annual conference held in San Francisco, CA in August of 2025. The presentation and subsequent publication presented a pedagogical framework for a course on Critical AI studies. The course was intended to introduce undergraduate students in the Arts and Humanities to both the technical aspects of AI model training, as well as selections of different readings grounded in Media Theory, in the hopes that they would walk away from the course with the ability to critique AI as a media form.
As a demonstration of a final project that students would be expected to complete, I trained a StyleGAN3 image generation model, positioning both the model and the training process as a site for aesthetic and critical inquiry.
The dataset consisted of 2,200 images taken on a Fujifilm X-S20 camera during a single walk through San Francisco’s Golden Gate Park on August 3, 2025, between 1:30 p.m. and 4:45 p.m. The temporal and geographic constraints functioned as deliberate aesthetic parameters on the production of the dataset , emphasizing how varying material constraints can impact both the model training process, as well as the possibilities found within the final produced latent space of the model.
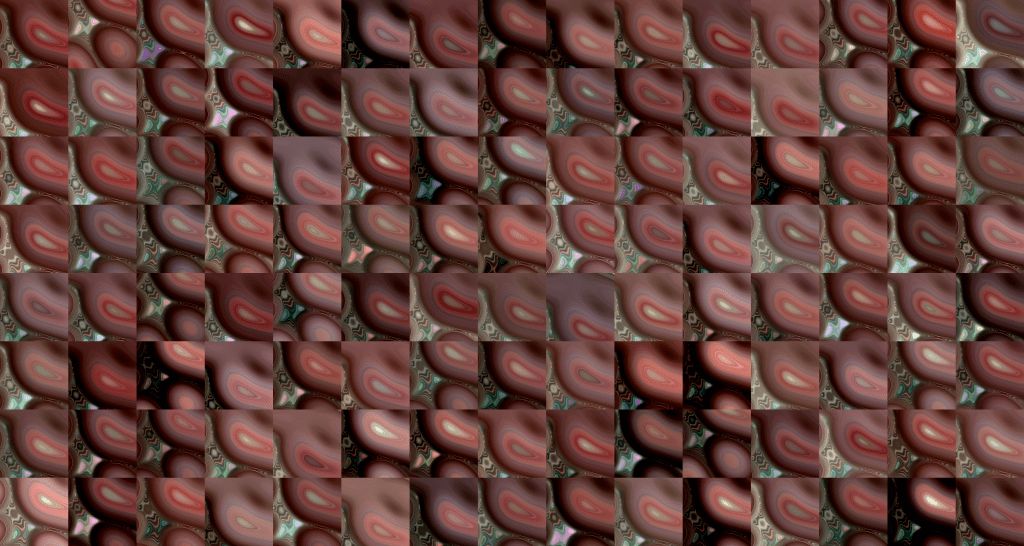
Using this curated dataset, I trained a StyleGAN3 model—NVIDIA’s open-source generative adversarial network—on a Google Colab notebook with access to A100 GPUs with over 48 hours of continuous training. The generated images reflected and reconfigured the park’s visual textures: repeated structures, tonal ranges, and color palettes emerged that echoed Golden Gate Park’s distinctive environment while abstracting it through the model’s representational logic.
This project foregrounds dataset construction as an aesthetic practice, making visible the interpretive and situated decisions, as well as the material labor, that shape model building, impacting and limiting the potential generations that can be produced by a latent space built using data that has been intentionally limited to specific aesthetic constraints.
The following images depict random samplings of the original training data followed by random generations of images produced at varying lengths in the training process, ending at 48 hours.